Diferentes formas de criar um DataFrame
Cinco formas diferentes de criar um DataFrame no Pandas
O DataFrame é um objeto da biblioteca do Pandas que é muito precioso para qualquer pessoa que está trabalhando com análise de dados. O fato é que esse objeto nos permite armazenar um conjunto de dados em formato de tabela, o que é formato muito comum de se armazenar grandes volumes de dados, sejam eles numéricos ou categóricos.
Na maioria dos casos, nós obtemos um conjunto de dados em um arquivo CSV ou XLSX (dentre outros) para fazer o tratamento dele. No entanto, é possível que nós estejamos desenvolvendo o nosso próprio dataset com base em dados que estamos gerando, seja com base em um experimento, uma pesquisa ou mesmo uma simulação.
Com base nisso, o objetivo deste artigo é auxiliar você a criar o seu próprio objeto DataFrame, te apresentando cinco formas distintas de alcançar o mesmo resultado. Caberá a você decidir aquela que será mais conveniente, tendo em vista o seu cenário e a sua aplicação.
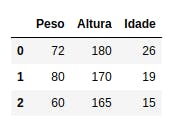
Antes de iniciarmos com os cinco métodos, já gostaria de adiantar que, em todos os casos, utilizaremos a função a função DataFrame da biblioteca do Pandas para criar esse objeto. A diferença aparecerá no tipo de dado que iremos passar como parâmetro para essa função. Além disso, os dados utilizados em todos os exemplos serão os mesmos e, portanto, todos os códigos dos exemplos resultarão no DataFrame apresentado na figura abaixo:
1. Array Bidimensional + Lista de Colunas
A primeira forma é mais adequada quando você já tem (ou pode facilmente criar) um array bidimensional que contenha os dados que você deseja armazenar. Nesse caso, as linhas do seu array devem conter diferentes observações, enquanto as colunas devem ser diferentes características, pois os dados serão alocados dessa mesma forma no DataFrame.
Em outras palavras, as linhas do seu array serão as linhas do DataFrame, assim como as colunas do array serão as colunas do DataFrame. Contudo, lembre-se de que você vai precisar definir quais serão os labels (nomes) da suas colunas (utilizando o parâmetro columns); do contrário, serão criados labels automáticos para elas.
Para entender como funciona esse tipo de criação, veja o exemplo abaixo, o qual foi desenvolvido no Jupyter Notebook:
import pandas as pd import numpy as np array = np.array([[72, 180, 26], [80, 170, 19], [60, 165, 15]]) df = pd.DataFrame(data=array, columns=['Peso', 'Altura', 'Idade'])
Observe que, nesse exemplo, foi criado um array bidimensional manualmente. Em cada linha (lista mais interna) temos um conjunto de características, a saber, peso, altura e idade. Ao todo, temos 3 linhas e 3 colunas. Esse array consiste nos dados do DataFrame (parâmetro data). Para definir as colunas do DataFrame precisamos utilizar o parâmetro columns, e atribuir a ele uma lista de strings, em que cada string representa o label que queremos atribuir a cada uma das três colunas (Peso, Altura e Idade).
2. Dicionário de Listas
Nesse segundo método, passaremos um dicionário de listas. As chaves (keys) desse dicionário serão os nomes das colunas do DataFrame, os valores (values) do dicionário serão os dados de cada coluna. Sendo assim, não é necessário utilizar o parâmetro columns; nesse caso, basta passar o dicionário de listas como parâmetro para a função DataFrame. Veja o exemplo abaixo:
import pandas as pd
dl = {'Peso': [72, 80, 60], 'Altura': [180, 170, 165], 'Idade': [26, 19, 15]}
df = pd.DataFrame(dl)3. Lista de Dicionários
Esse método é o completo oposto do anterior. Além de utilizarmos uma lista de dicionários, cada dicionário da lista será uma linha do DataFrame. Observando o exemplo, você perceberá que cada dicionário possui chaves que correspondem aos nomes das colunas do DataFrame, as quais são seguida pelo valor que deve ser atribuído àquela linha específica. Esse método, claramente, é mais trabalhoso, pois exige que você coloque os labels das colunas em todos os dicionários. Porém, é mais uma opção…
import pandas as pd
ld = [
{
'Peso': 72,
'Altura': 180,
'Idade': 26
},
{
'Peso': 80,
'Altura': 170,
'Idade': 19
},
{
'Peso': 60,
'Altura': 165,
'Idade': 15
}
]
df = pd.DataFrame(ld)4. Lista de Tuplas
Esse método é bem semelhante, a única diferença é que, ao invés dos dados serem um array bidimensional, nós passamos uma lista de tuplas. Cada tupla consiste em uma linha do seu DataFrame. Como as tuplas contém apenas os dados, é necessário utilizarmos o parâmetro columns para definir as colunas do nosso DataFrame. Veja o exemplo abaixo:
import pandas as pd
lt = [
(72, 180, 26),
(80, 170, 19),
(60, 165, 15)
]
df = pd.DataFrame(lt, columns=['Peso', 'Altura', 'Idade'])5. Dicionário de Series
É muito comum você ouvir que a Series é a coluna de um DataFrame. Isso se torna ainda mais claro quando você cria um DataFrame utilizando esse último método. Podemos criar também um dicionário com Series, em que as chaves (keys) são os nomes das colunas, e os valores (values) são Series que contém os dados de cada coluna do DataFrame. Assim, basta inserir esse dicionário de Series que obteremos o DataFrame. Observe o exemplo abaixo:
import pandas as pd
ds = {'Peso': pd.Series([72, 80, 60]), 'Altura': pd.Series([180, 170, 165]), 'Idade': pd.Series([26, 19, 15])}
df = pd.DataFrame(ds)É isso, galera! Gostou desse post? Então, não deixa de me seguir no Instagram ou no Canal do Telegram para acompanhar todas as novidades do Blog e do canal do YouTube. Um abraço e até a próxima!